Seenull Repo 发布
初衷
在github的日子里,不时会为找到一个称心如意的repo而兴奋不已。接下来就是马不停蹄的提起键盘git clone、看Readme、测效果。 但快乐的时光是短暂的,我时常为找一个类似功能的repo而伤透脑筋,除了搜索功能,我很少有获知其它repo的方式,尤其是相对冷门但是却满足我需求的repo。
灵感
我发现了一个规律,一个用户关注的领域范围是有边界的,用户存在着关注画像。这种关系若以词向量的方式表示,那么!相似度最高的repo关注者一定是同画像用户。所以,仓库是可以分组的,关注点可以用无限维度的词语表示。
以github上’https://github.com/ownerA/repo1’举例,‘ownerA/repo1’其相似度结果最高的‘ownerB/repo2’关注者一定是‘ownerA/repo1’的关注者。那么通过词向量,输入‘ownerA/repo1’,则能发现‘ownerB/repo2’。所以,不必通过关键词匹配的方式去找同类repo的工具就此诞生。暂以seenull repo 发布。
原理
还不明白什么意思?在词向量最典型应用中,通过自然语言库:
‘中国’ similar ‘北京’、‘上海’、‘广州’,
‘美国’ similar ‘华盛顿’、‘洛杉矶’、‘纽约’,
‘java’ similar ‘c#’、‘程序’、‘javascript’。
同时词向量还可以表示这种关系:
男人-男孩 similar 女人-?
内蒙-呼和浩特 similar 河北-?
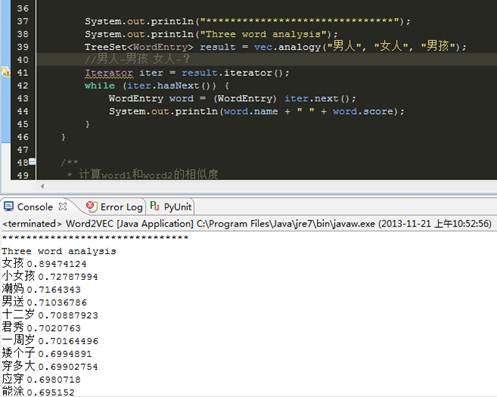
有比“女孩”更好的标准答案吗?紧跟其后的小女孩、潮妈相似度极高。
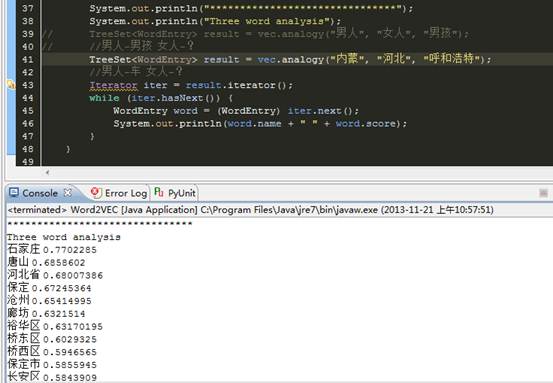
石家庄 完美出现,我都想用词向量做数学运算了:)
实践-技术点
- 定期爬虫
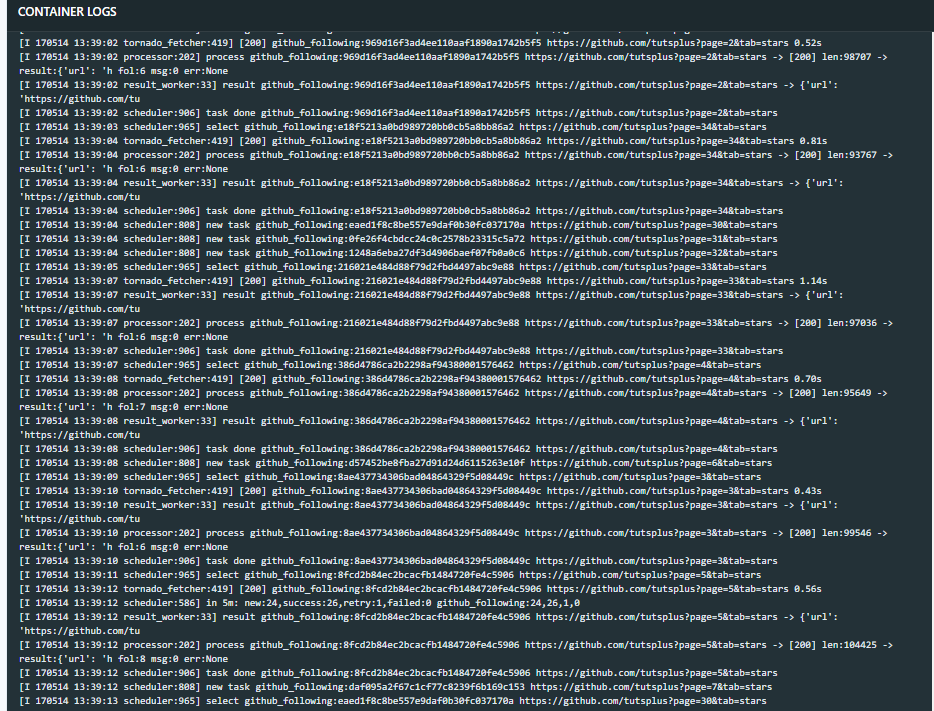 抓取基础数据,用户对仓库的关注信息
抓取基础数据,用户对仓库的关注信息 - 词向量训练模型,目前用到word2vec
- docker容器,微服务架构,采集、训练、web服务、页面分离
- 响应式布局
TODO
- 搜索界面通过异步访问github api,对呈现仓库的description、star、fork 等信息的描述。
- 目前发布的模型基于29w个页面star记录,采集的数量级需提升。
- NOG(Not Only Github)探究,通用模型的行业化运用设计,如更精确的商品查找模型、歌曲搜索模型。
Written on May 14, 2017
请我喝杯咖啡吧